mirror of
https://codeberg.org/forgejo/forgejo.git
synced 2024-11-14 14:49:32 +01:00
This PR is for: * https://github.com/go-gitea/gitea/issues/20231 Now, when a user searches `word`, they always see `/{word}.txt` before `/{w}e-g{o}t-{r}esult.{d}at` Demo: When searching "a", "a.ext" comes first. Then when searching "at", the longer matched "template" comes first. <details> 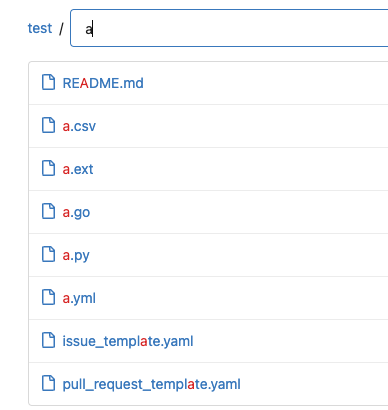 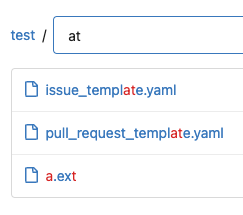 </details> This PR also makes the frontend tests could import feature JS files by introducing `jestSetup.js` Co-authored-by: delvh <dev.lh@web.de> Co-authored-by: silverwind <me@silverwind.io>
{kind=link}
{kind=link}
118 lines
4 KiB
JavaScript
118 lines
4 KiB
JavaScript
import $ from 'jquery';
|
|
|
|
import {svg} from '../svg.js';
|
|
const {csrf} = window.config;
|
|
|
|
const threshold = 50;
|
|
let files = [];
|
|
let $repoFindFileInput, $repoFindFileTableBody, $repoFindFileNoResult;
|
|
|
|
|
|
// return the case-insensitive sub-match result as an array: [unmatched, matched, unmatched, matched, ...]
|
|
// res[even] is unmatched, res[odd] is matched, see unit tests for examples
|
|
// argument subLower must be a lower-cased string.
|
|
export function strSubMatch(full, subLower) {
|
|
const res = [''];
|
|
let i = 0, j = 0;
|
|
const fullLower = full.toLowerCase();
|
|
while (i < subLower.length && j < fullLower.length) {
|
|
if (subLower[i] === fullLower[j]) {
|
|
if (res.length % 2 !== 0) res.push('');
|
|
res[res.length - 1] += full[j];
|
|
j++;
|
|
i++;
|
|
} else {
|
|
if (res.length % 2 === 0) res.push('');
|
|
res[res.length - 1] += full[j];
|
|
j++;
|
|
}
|
|
}
|
|
if (i !== subLower.length) {
|
|
// if the sub string doesn't match the full, only return the full as unmatched.
|
|
return [full];
|
|
}
|
|
if (j < full.length) {
|
|
// append remaining chars from full to result as unmatched
|
|
if (res.length % 2 === 0) res.push('');
|
|
res[res.length - 1] += full.substring(j);
|
|
}
|
|
return res;
|
|
}
|
|
|
|
export function calcMatchedWeight(matchResult) {
|
|
let weight = 0;
|
|
for (let i = 0; i < matchResult.length; i++) {
|
|
if (i % 2 === 1) { // matches are on odd indices, see strSubMatch
|
|
// use a function f(x+x) > f(x) + f(x) to make the longer matched string has higher weight.
|
|
weight += matchResult[i].length * matchResult[i].length;
|
|
}
|
|
}
|
|
return weight;
|
|
}
|
|
|
|
export function filterRepoFilesWeighted(files, filter) {
|
|
let filterResult = [];
|
|
if (filter) {
|
|
const filterLower = filter.toLowerCase();
|
|
// TODO: for large repo, this loop could be slow, maybe there could be one more limit:
|
|
// ... && filterResult.length < threshold * 20, wait for more feedbacks
|
|
for (let i = 0; i < files.length; i++) {
|
|
const res = strSubMatch(files[i], filterLower);
|
|
if (res.length > 1) { // length==1 means unmatched, >1 means having matched sub strings
|
|
filterResult.push({matchResult: res, matchWeight: calcMatchedWeight(res)});
|
|
}
|
|
}
|
|
filterResult.sort((a, b) => b.matchWeight - a.matchWeight);
|
|
filterResult = filterResult.slice(0, threshold);
|
|
} else {
|
|
for (let i = 0; i < files.length && i < threshold; i++) {
|
|
filterResult.push({matchResult: [files[i]], matchWeight: 0});
|
|
}
|
|
}
|
|
return filterResult;
|
|
}
|
|
|
|
function filterRepoFiles(filter) {
|
|
const treeLink = $repoFindFileInput.attr('data-url-tree-link');
|
|
$repoFindFileTableBody.empty();
|
|
|
|
const filterResult = filterRepoFilesWeighted(files, filter);
|
|
const tmplRow = `<tr><td><a></a></td></tr>`;
|
|
|
|
$repoFindFileNoResult.toggle(filterResult.length === 0);
|
|
for (const r of filterResult) {
|
|
const $row = $(tmplRow);
|
|
const $a = $row.find('a');
|
|
$a.attr('href', `${treeLink}/${r.matchResult.join('')}`);
|
|
const $octiconFile = $(svg('octicon-file')).addClass('mr-3');
|
|
$a.append($octiconFile);
|
|
// if the target file path is "abc/xyz", to search "bx", then the matchResult is ['a', 'b', 'c/', 'x', 'yz']
|
|
// the matchResult[odd] is matched and highlighted to red.
|
|
for (let j = 0; j < r.matchResult.length; j++) {
|
|
if (!r.matchResult[j]) continue;
|
|
const $span = $('<span>').text(r.matchResult[j]);
|
|
if (j % 2 === 1) $span.addClass('ui text red');
|
|
$a.append($span);
|
|
}
|
|
$repoFindFileTableBody.append($row);
|
|
}
|
|
}
|
|
|
|
async function loadRepoFiles() {
|
|
files = await $.ajax({
|
|
url: $repoFindFileInput.attr('data-url-data-link'),
|
|
headers: {'X-Csrf-Token': csrf}
|
|
});
|
|
filterRepoFiles($repoFindFileInput.val());
|
|
}
|
|
|
|
export function initFindFileInRepo() {
|
|
$repoFindFileInput = $('#repo-file-find-input');
|
|
if (!$repoFindFileInput.length) return;
|
|
|
|
$repoFindFileTableBody = $('#repo-find-file-table tbody');
|
|
$repoFindFileNoResult = $('#repo-find-file-no-result');
|
|
$repoFindFileInput.on('input', () => filterRepoFiles($repoFindFileInput.val()));
|
|
|
|
loadRepoFiles();
|
|
}
|